Spracherzeugung aus Audiosampels geschrieben am 11.09.2016
Dies ist ein Versuch, Texte 'on the fly' vorlesen zu lassen.
Idee
Irgendwo habe ich aufgeschnappt, dass die Sprache aus Phonemen besteht. Man spricht also nicht in Buchstaben, sondern in Lauten. Wenn man nun das Set aus Lauten nimmt, könnte man damit wieder ganze Sätze erzeugen.
Vorgehen
Als erstes habe ich mir die Liste der Phoneme auf de.wiktionary.org/../Phoneme_und_Grapheme angesehen. Die Liste der Phoneme dient mir als Vorlage für die zu erzeugenden Audiosamples. Dazu habe ich aus den dort enthaltenen Beispielwörtern Sätze gebildet:
Ein *Tier in der *Mitte der *Sonne ist *Reis auf.
Die *Band ist im *Rhythmus der Musik.
Die *Malerei ist *hell oder dunkel.
Auf dem *Bett ist *Physik *gewiss der *Beginn einer *Brücke über alles.
Im *Raum herrscht *Ebbe und der *Fisch *oder der *Adler sehen zu.
Die *Bauten im *Zoo haben ein *Rad aus *Pappe auf dem Dach.
In der *Prüfung *kommen *Wald, *Mutter und *Pferd auf einen *Barzar nicht vor.
Die *Freiheit ist *nie *zufällig wie *Schnee aber weiß.
Ein *Hut vom *Pirat über dessen *Mähne sitzt.
Ein großen *Schuh, der *Clown am Fuße hat.
Fliegt der *Müll im hohen *Bogen die *Brüder wussten nichts.
Doch ein *Loch wo *Häuser den *Fuchs einen *Kaffee anbieten.
Oh wie *schön ist *Spanien im *Dirndl in diesem *Jahr zu sehen.
Das kleine *Instrument passt ins *Auto genau.
Aber *geben wir den *zwölf einen *Topf anbei,
so ist auf dem *Berg keine *Qualle zu sehen.
Die *Synode der *Familie besteht.
In der *Reihe steht ein *Beamter wie jeder andere auch.Die Sätze sind schon fast philosophisch :-o
Die Sternchen markieren die Worte, aus denen ich die Samples geschnitten habe.
Warum habe ich Sätze gebildet?
Wenn ich die Worte in Sätze einarbeite, ist ein neutrales Ergebnis möglich.
Audioarbeit
Ich habe mit einem Olympus LS-5 die oben genannten Sätze mehrmals eingesprochen. Mehrmals, um erstmal die Stimme warm zu reden und zum zweiten genug Material zu haben. Nach circa 10 Versuchen war ich zufrieden und habe die letzten zwei Aufnahmen weiterverarbeitet. Mit Audacity habe ich die Phoneme herausgeschnitten:
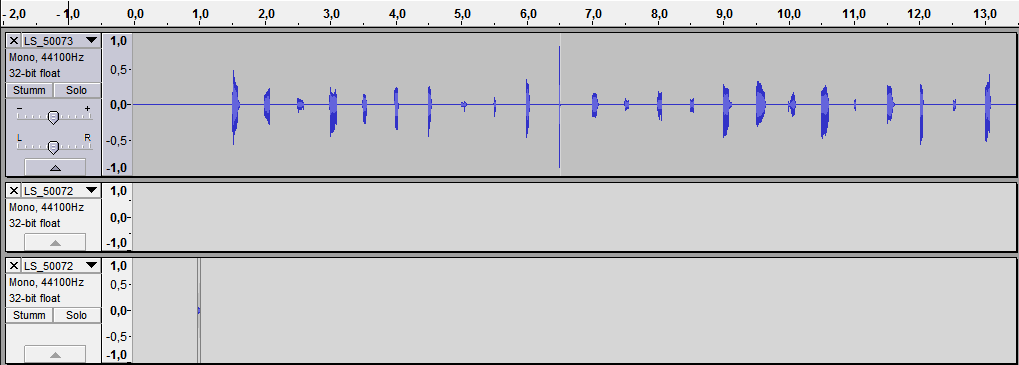
Ich habe sie im Abstand von 0,5 Sekunden in eine neue Datei abgelegt.
Programmieren
Da das Ganze im Webbrowser laufen soll, habe ich JavaScript und das Audiotag von HTML5 benutzt.
Im ersten Schritt habe ich den eingegebenen Text nach der Tabelle auf die Phoneme umgemappt:
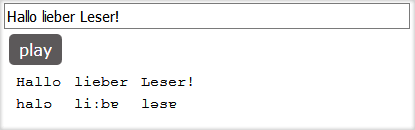
In der unteren Zeile kann man das gemappte Ergebnis sehen.
Abspieltechnik
Im ersten Anlauf benutzte ich die Scrubbing-Technik. Dazu lade ich meine Samples, die in einer Datei gespeichert sind, in ein Audioelement. Die Stelle, an der das Phonem liegt, wird angesprungen und abgespielt. Dann das nächste, dann das nächste... und man sollte einen gesprochenen Satz hören.
Auf das Script gehe ich hier nicht näher ein. (download Version 0.1: projekt_sprache.zip 472.69kb)
ausprobieren (Version 1)
Nun, wie jeder hören kann, funktioniert es mehr oder weniger gut. Zum einen muss die Übersetzung vom Wort zum Phonem noch optimiert werden, und zum anderen sind eventuell noch Varianten nötig.
TODO/Was noch zu tun wäre
Die Scrubbing-Technik funktioniert zwar, aber es könnte flüssiger sein. Momentan geht zu viel Zeit beim Umherspringen verloren. Deshalb ist der nächste Schritt, dynamisch eine Audiodatei zu erzeugen und dann abzuspielen.
Außerdem werden nicht immer die richtigen Phoneme benutzt – für einige Buchstaben (oder Kombinationen) gibt es mehrere Möglichkeiten. Zum Beispiel wird das "ch" in "ich" und "auch" unterschiedlich ausgesprochen.
neue Version [19.9.2016]
Phonem-Filter verbessert: Das Mapping und die Erkennung der Phoneme wurden optimiert, was zu einer besseren Sprachausgabe führt.
neue Version [20.9.2016]
Nummern in Worte umwandeln: Die Umwandlung von Zahlen in ausgeschriebene Worte ist nun möglich, z. B. "3in1".
Fehlerbehebung: Unbekannte Zeichen werden nun ignoriert, was die Endlosschleifen aus der vorherigen Version verhindert.
neue Version [24.9.2016]
iOS-Kompatibilität: Die Anwendung funktioniert nun auch auf iOS. Ein wichtiger Hinweis ist, dass der detune-Effekt auf iOS nicht verfügbar ist, was in der neuen Version berücksichtigt wurde.
Audio-Überlappung: Die Audiosamples können jetzt überlappen, was zu einer flüssigeren Sprachausgabe führt und den Übergang zwischen den Phonemen verbessert.
download
Wer Interesse hat kann das aktuelle Projekt auf github finden und laden.